
Overview
Raven, a system designed to optimize prediction queries that combine traditional data processing (joins, filters, featurization) with machine learning (ML) inference. Traditionally, these two components have been optimized in isolation. Raven breaks these silos by using a unified intermediate representation (IR) that captures both relational and ML operators in a single graph structure.
Tis unified view enables two main categories of optimisations:
-
Logical Cross-Optimizations: Passing information between the data and ML parts to speed up the execution and prune the prediction model.
-
Logical-to-Physical Transformations: Deciding the most efficient runtime for each operator, whether it be a relational database engine, a standard ML runtime, or a hardware-accelerated deep learning framework.
Logical Cross-Optimization
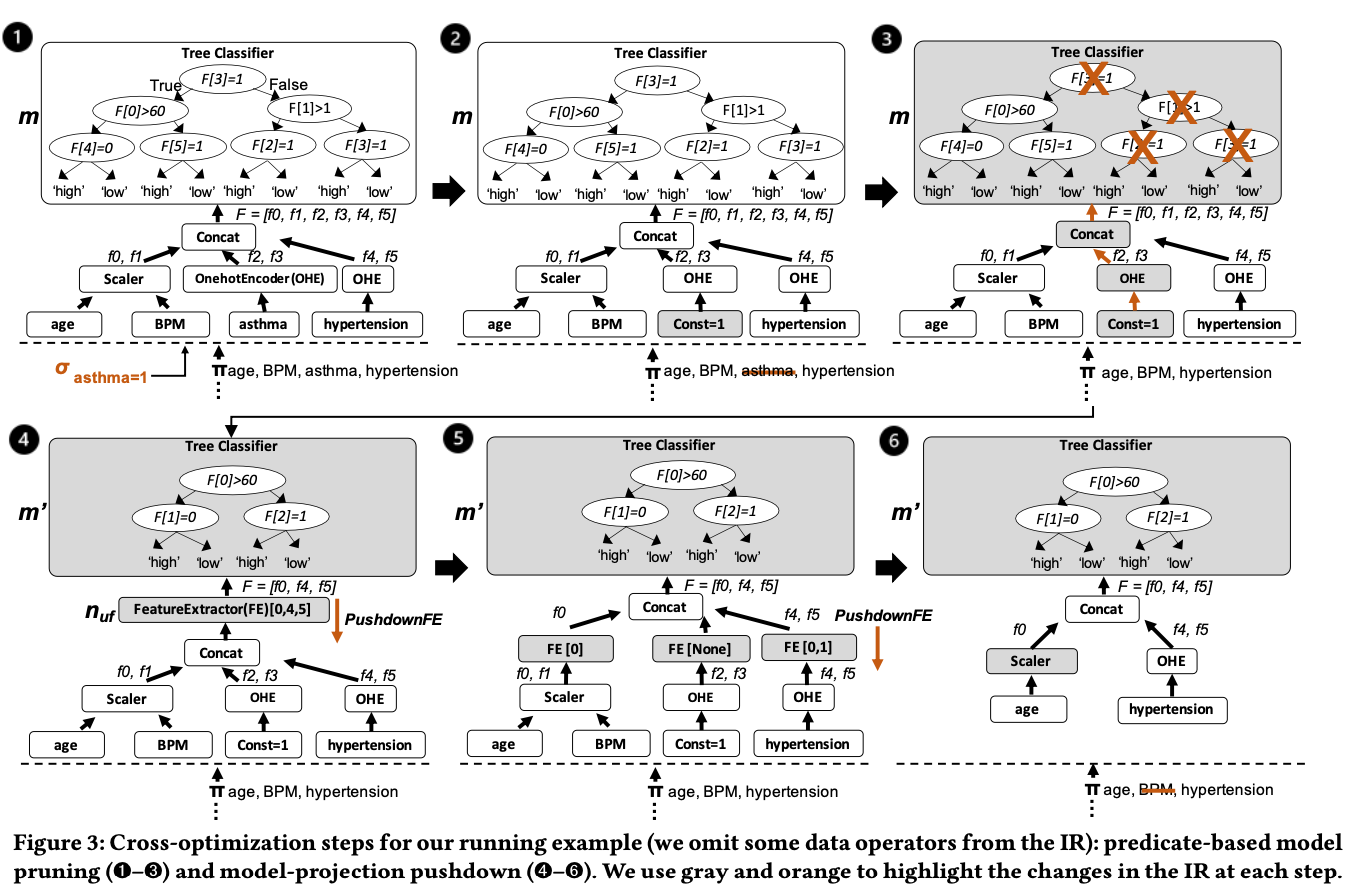
Predicate-based model pruning.
This optimization identifies data predicates in the WHERE clause and passes them to the trained pipelines to simplify the model. For tree-based models, it uses equality or range predicates to prune branches that are no longer reachable based on the data filters. For linear models, it pre-computes parts of the ML operations where inputs are known constants. For example, in filter condition of WHERE clause, the feature value is set to certain categorical value.
Model-projection pushdown.
This rule identifies unused features—either those never used by the model or those rendered unnecessary after pruning—and pushes “projections” down toward the data source. This allows the database to avoid scanning unnecessary columns and can even eliminate entire joins if a table only provided features that the model no longer needs
Logical-to-Physical Transformations
Raven aims to combine all operators into a single runtime when possible, proposing three primary paths:
- MLtoSQL: Converts ML operators (like tree-based models) into native SQL nested CASE expressions. This allows the model to run directly in the database engine, avoiding data movement and initialization costs.
- MLtoDNN: A novel approach that converts traditional ML models (Random Forests, LightGBM) into equivalent tensor-based DNNs**. **These models run in high-performance engines like ONNX Runtime, which provide out-of-the-box acceleration for GPUs and FPGAs.
- No transformation: The model is executed as-is using a standard ML runtime (e.g., ONNX Runtime on CPU).
And the problem rise, when a prediction query come in, how to choose which transformation:
So the paper also propose a method “Data-Driven Optimization Strategies” to pick the best path.
It based on current benchmark dataset, and apply these three optimizations seperately, it can collect the statics. Based these statics, it propose three approach to distinguish which optimization to use.
-
ML-Informed Rule-based: A decision tree trained on benchmarks identifies the most critical features (e.g., number of inputs, tree depth) to create simple fixed rules for production, such as: “If features > 100, use MLtoDNN; else if tree depth ≤ 10, use MLtoSQL”
-
Classification-based: A random Forest classifier trained on historical benchmark to predict which runtime for a specific query and model. The feature is manually defined in advance. This strategy showed the lowest variance in performance
-
Regression-based: Uses a Decision Tree regression model to estimate the actual latency. And it directly consider the type of optimization as feature. when selection, the model estimate cost of all three optimizations and choose the one with the lowest estimated time.
Points of Interest: MLtoDNN
In many contexts, traditional ML models are considered more efficient than DNNs because they are structurally simpler. However, Raven’s motivation for this “counterintuitive” transformation is that traditional ML models lack a standard computation abstraction, making them difficult to optimize for modern hardware like GPUs.
Raven leverages a tool called Hummingbird to translate traditional ML operators into equivalent tensor operations. By representing a decision tree as a series of tensor computations, Raven can “trick” Deep Learning engines like PyTorch or ONNX Runtime into accelerating them using their existing GPU/FPGA kernels.
The results show that while moving data to a GPU involves some overhead, the sources note that this strategy is highly beneficial for complex models (e.g., large ensembles with many trees or high depth), where it can deliver up to an 8× speedup.
Therefore, I think is should be quite interesting direction.
Go against the grain, for complex ML models, just convert it into a DNN models, and use hardware to accelerate the inference efficiency in system-level.