Tabular data remains the dominant data format in real-world analytics and database systems. Despite strong empirical performance of modern models, feature embedding continues to be the fundamental bottleneck in tabular learning. This post summarizes recent insights on tabular foundation models and motivates a unified solution inspired by image inpainting.
1. Traditional Tabular Learning Paradigm
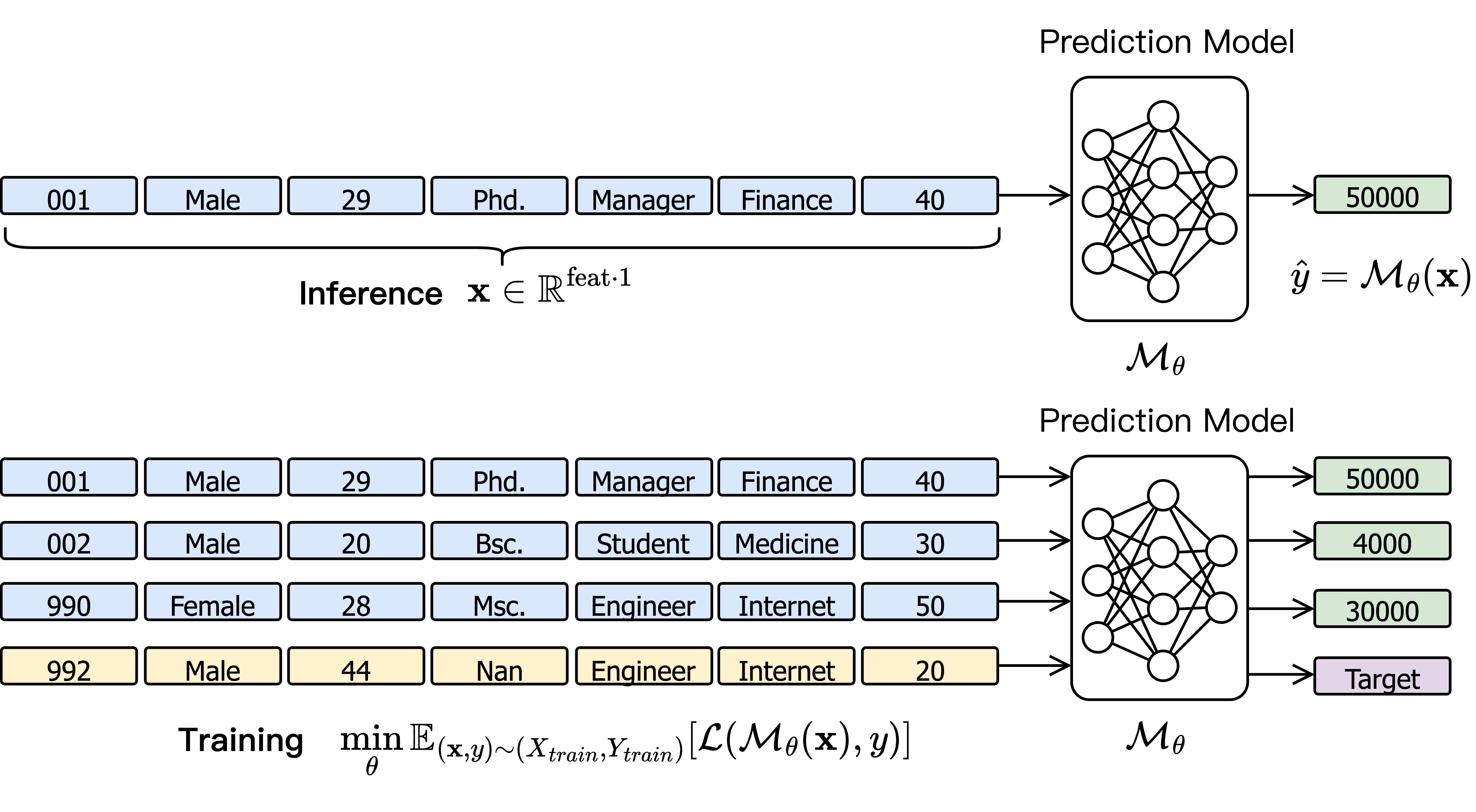
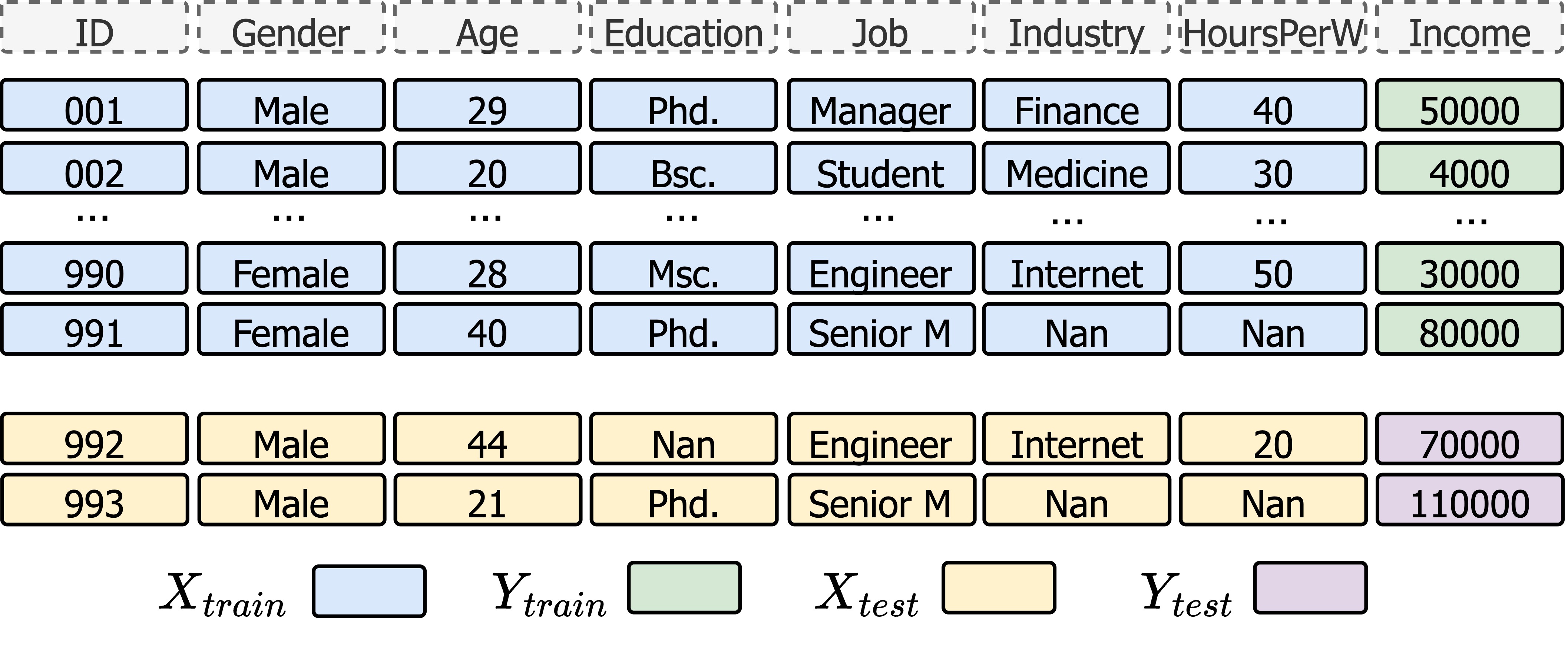 In the classical setting like the figure shows, a tabular model learns a fixed mapping:
In the classical setting like the figure shows, a tabular model learns a fixed mapping:
where $\mathbf{x}$ is a feature vector and $y$ is the target attribute.
The model compresses knowledge into parameters during training and predicts each instance independently at inference time.
Inference and training can be shown like this
Limitations
- Ignores relationships among instances (assume IID between instances)
- Relies heavily on task-specific feature engineering
- *Poor generalization across datasets and tasks
2. Tabular Foundation Models: Learning with Context
In tabular foundation models, the input is extended to include a context set of sampled training instances, as the figure shows
\[\mathbf{x} = (\textbf{x}_{ctx}, \textbf{y}_{ctx}) || (\textbf{x}_{test}, \textbf{y}_{test}) \;\; \text{where} \;(\textbf{x}_{ctx}, \textbf{y}_{ctx})\sim(X_{train}, Y_{train})\]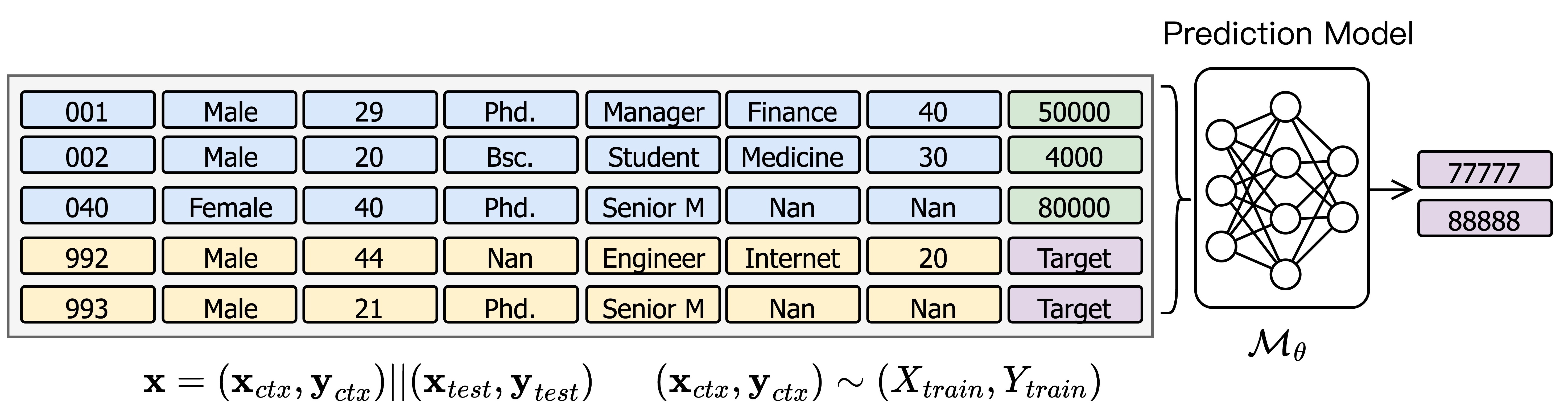
This enables the model to learn not only the feature-to-target mapping, but also instance-level relationships within the context.
Key advantage: improved generalizability, as predictions adapt dynamically to contextual signals instead of relying solely on fixed embeddings.
We can apply the scaling laws on these problem and use this model for different prediction tasks.
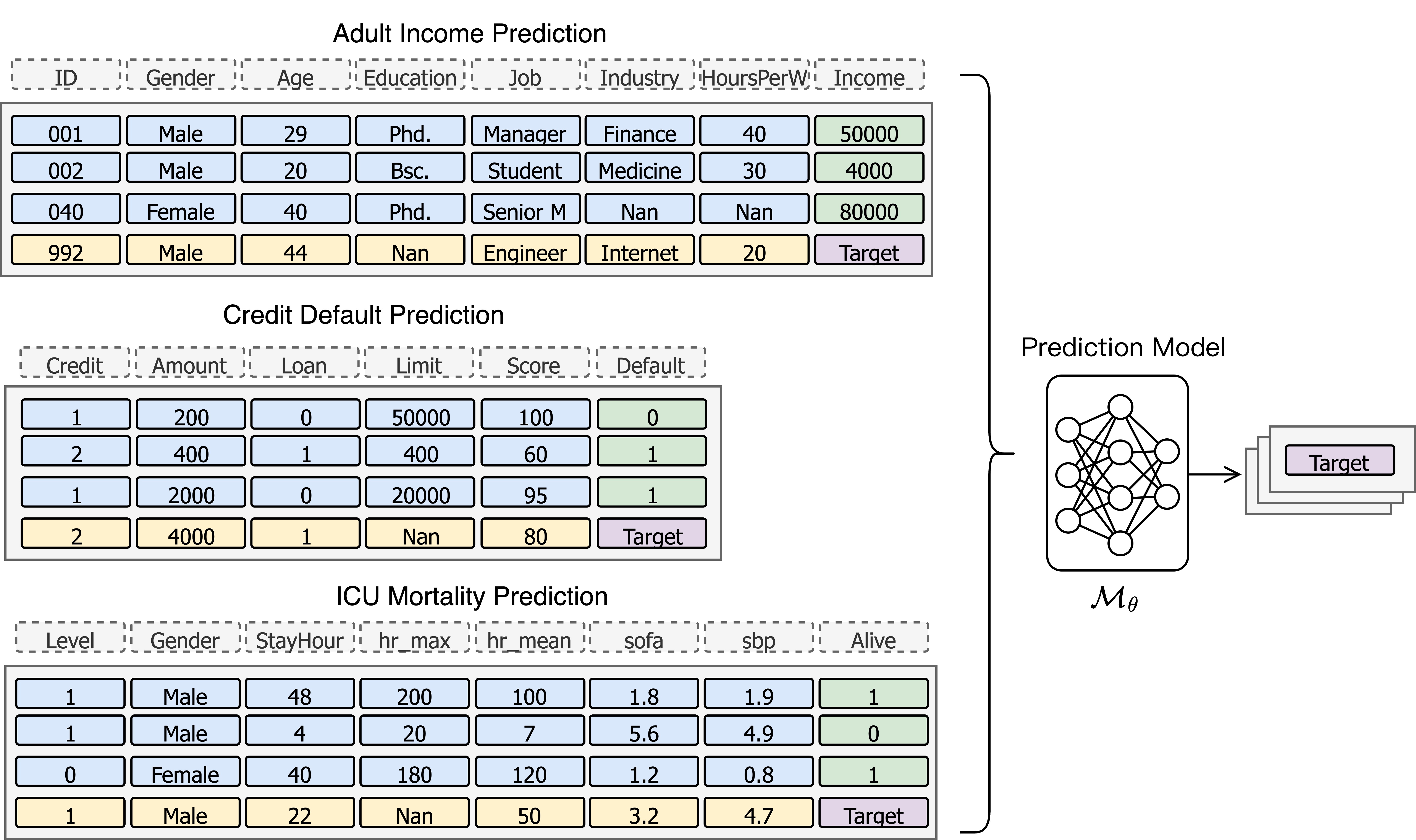
3. Analogy to Image Inpainting
This paradigm closely resembles image inpainting in computer vision:
| Image Inpainting | Tabular Foundation Modeling |
|---|---|
| Image Inpainting | Tabular Foundation Modeling |
| Masked pixels are inferred | Target / missing values are inferred |
| Context = surrounding pixels | Context = sampled instances |
| Encoder–decoder architecture | Context-aware encoder |
Both problems share a common structure: predicting masked values using contextual information. Image inpainting typically employs encoder–decoder or Transformer-based architectures, suggesting a shared high-level solution for tabular learning.

In fact, image inpainting is a sophisticated research area where Vision Transformers (ViT) achieve state-of-the-art performance. Bridging these two problem formulations could significantly accelerate progress in tabular modeling.
4. Difference between tabular data and image
4.1 Feature Embedding vs. Pixel Embedding
- Pixel embedding
- Native RGB representation
- Uniform and task-agnostic
- Shared across all images
- Feature embedding
- Depends on heterogeneous data types
- Often task- or dataset-specific
- Limited transferability

Feature embedding is therefore the core challenge in tabular learning.
4.2 Tabular Format vs. Image Format
| Property | Tabular Data | Image Data |
|---|---|---|
| Ordering | Permutation-invariant | Fixed spatial order |
| Semantics | Orthogonal (rows & columns) | Local (neighbor pixels) |
| Structure | Schema-driven | Grid-based |
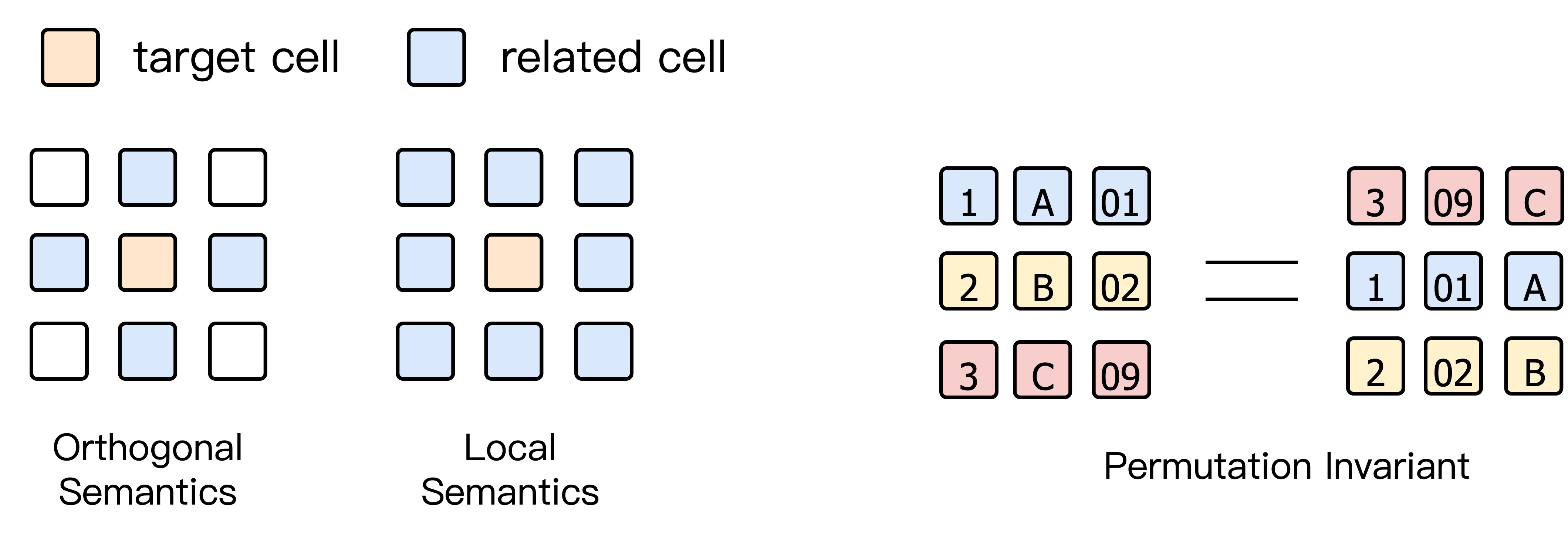
While self-attention is permutation-invariant, tabular data requires explicit modeling of orthogonal semantics across rows and columns.
5. Limitations of Existing Tabular Foundation Models
Most current models (e.g., TabPFN, TabICL) adopt simplifying assumptions:
- Only numerical and categorical features are supported
- Categorical features are handled via per-column ordinal encoding
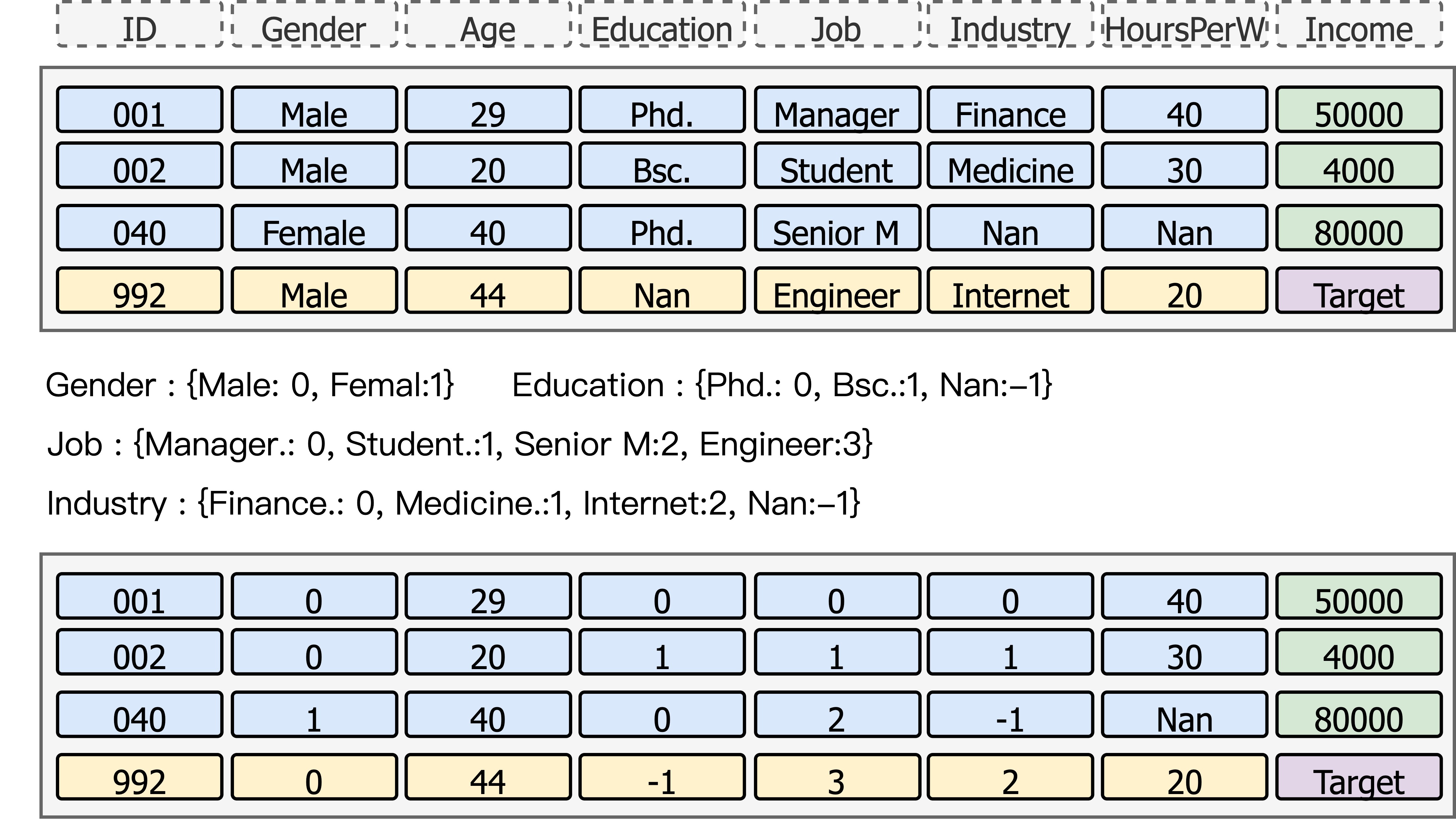
This leads to:
- Artificial partial-order noise for categorical values
- Duplicated embeddings for identical values in different columns
- Poor scalability to high-cardinality features
As a result, learned embeddings overfit to specific datasets and tasks.
6. Toward a Unified Feature-to-Embedding Mechanism
Feature embedding—not model architecture—is the fundamental obstacle in tabular learning.
By:
- Introducing context-aware learning,
- Designing a unified feature-to-embedding mechanism,
- Drawing inspiration from image inpainting,
we move closer to general, transferable, and robust tabular foundation models.