Preface
Recently, I have been working on revising a VLDB paper, where our objective is to integrate relational data within an RDBMS to support analytical prediction tasks. From my perspective, regardless of the contributions claimed in the paper, what we fundamentally accomplish is following the database schema and reorganizing the data as a relational graph (as illustrated in the figure below). Subsequently, we apply Graph Neural Networks (GNNs) to aggregate information within the graph structure, thereby augmenting tuple representations for predictive modeling. I first encountered this research direction through RelBench and 4DBInfer.
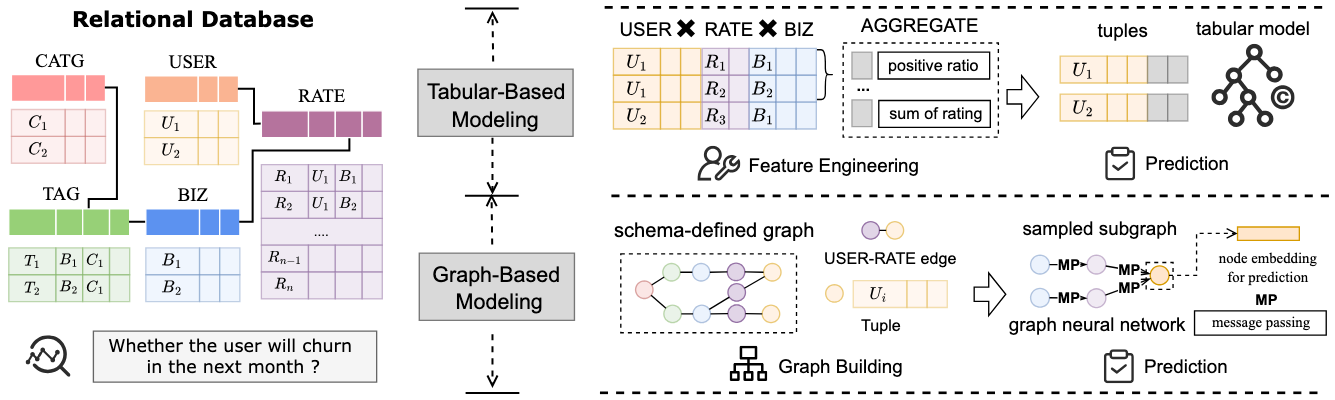
However, I quickly realized that this approach is challenging to scale in real-world industrial scenarios due to the computational overhead associated with building and maintaining relational graphs. Although the end-to-end analytical solution is attractive as a research topic—eliminating the need for manual data integration and feature engineering—it requires substantial supporting optimizations to become practically viable in production environments.
Setting aside the research aspects (which primarily prove a principle), an important question emerges: what do real-world enterprise-level data analytics solutions actually look like? This is a fundamental question that systems researchers need to understand and master. This post serves as a compilation of my findings and observations on this topic.
Overview
From an architectural abstraction perspective, we can divide the entire analytics pipeline into the following logical components:
- Source of Truth: The authoritative data repository
- Real-Time Feature Generation: Dynamic feature computation from streaming data
- Feature Store & Processing: Centralized feature management and serving
- Tabular Model Inference: Production model serving for predictions
Fundamentally, this pipeline still adheres to the traditional data science philosophy: data scientists aggregate tables, manually perform feature engineering to generate a flattened table, and then apply tabular models to this consolidated representation for prediction. However, enterprise-level systems distinguish themselves by ensuring that each step maintains scalability, reliability, and operates autonomously with minimal human intervention.
Let us examine each component in detail, along with the technologies commonly employed at each stage.
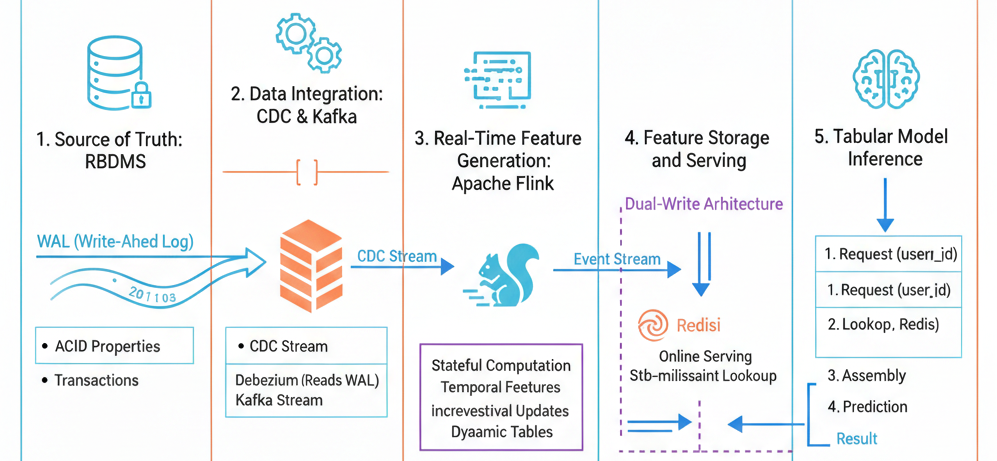
Source of Truth: RDBMS
In enterprise environments, RDBMS serve as the primary repository for operational raw data. For instance, banking systems utilize databases to store transactional records for each account. RDBMS are specifically designed to provide ACID properties (Atomicity, Consistency, Isolation, Durability) for data security while maintaining high throughput and low latency to satisfy business-critical operational requirements.
Importantly, the primary objective of data organization in RDBMS is to record ground truth frequently and securely—not to facilitate analytical queries. This design priority creates a fundamental tension: operational databases are optimized for transactional workloads (OLTP), not for the complex analytical queries (OLAP) required by machine learning and business intelligence applications. This architectural distinction directly conflicts with end-to-end research approaches that attempt to perform analytics directly on operational databases.
Real-Time Feature Generation: Apache Flink
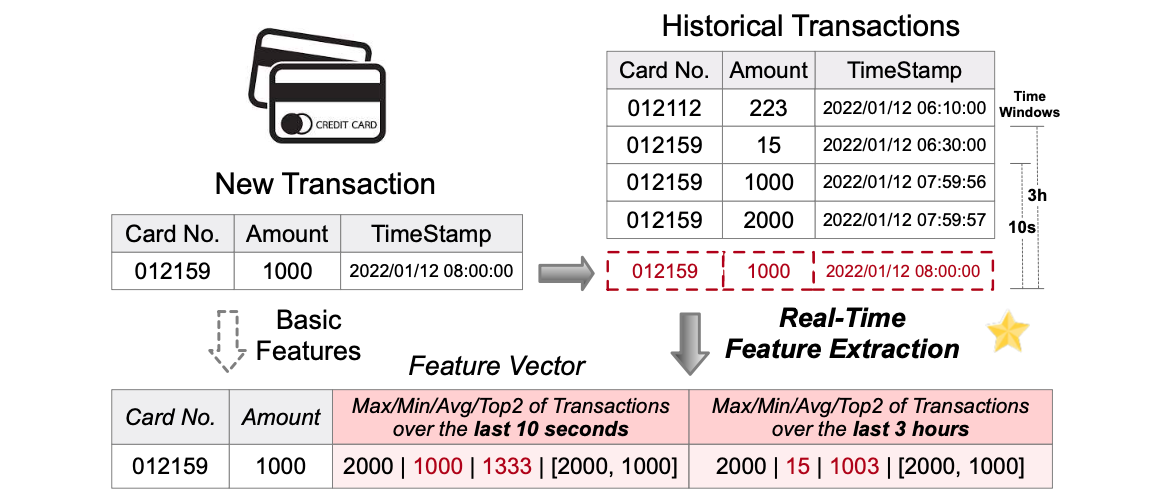
As illustrated in the figure from FEBench, the feature generation process involves applying pre-defined or task-specific operators to event streams, transforming these complex incremental changes into continuously maintained feature tables. This transformation layer bridges the gap between raw operational events and the features required for machine learning models.
Apache Flink is the predominant technology for this component. Flink is an open-source distributed stream processing framework specifically designed to execute continuous stateful computations over unbounded data streams. Its architecture makes it particularly well-suited for real-time feature engineering in production environments.
The key properties that make Flink suitable for feature generation include:
-
Stateful by Design: Flink maintains various forms of state including per-key state, window state, and join state. State serves as the fundamental data structure in Flink and directly represents temporal features that evolve over time. This enables the computation of sophisticated features such as rolling averages, counts, and aggregations without reprocessing historical data.
-
Event-Time Correctness: Flink supports event-time semantics, watermarks, and late event handling. This capability is crucial for analytical and machine learning features that depend on time windows, ensuring that features are computed correctly even when events arrive out of order or with varying delays.
-
Incremental Computation: Each new event produces a delta update that only affects the relevant keys or windows, rather than triggering full recomputation. This incremental approach enables efficient processing of high-volume streams while maintaining low latency.
Feature Store & Processing: Redis and OLAP Databases
Once Flink generates features, they must be persisted and served efficiently. The requirements for feature serving differ significantly between online and offline use cases:
Requirements for Online Serving:
- Fast access at inference time (sub-millisecond)
- Direct key-based lookups without joins or scans
- Stable, versioned feature vectors for consistency
Redis: Online Feature Serving
Redis, an in-memory key-value store, is the standard solution for online feature serving and real-time inference. Its characteristics make it ideal for this purpose:
- Sub-millisecond Latency: Memory-resident storage enables extremely fast access
- Key-Based Lookup: Simple retrieval pattern (e.g.,
GET user_id) without complex query processing - Extremely High QPS: Can handle millions of queries per second
- Flexible Data Models: Supports hashes, strings, JSON, and other structures
- Online Feature Cache: Serves as the primary source for real-time predictions
OLAP Databases: Offline Feature Warehouse
OLAP databases (such as ClickHouse, BigQuery, or DuckDB) serve the offline and analytical path. These systems are not designed for online inference; instead, they function as a feature warehouse for batch processing and analysis.
OLAP databases excel at:
- Large-Scale Scans: Efficiently processing billions of rows for analytical queries
- Historical Queries: Accessing time-series feature history for analysis
- Feature Validation and Debugging: Investigating feature distributions and anomalies
- Offline Training Dataset Construction: Building comprehensive training sets with point-in-time correctness
In the offline path, frameworks like Apache Spark can process data from OLAP databases to perform global analytics. This includes feature selection, model evaluation, drift detection, and model training. The OLAP database essentially serves as an offline feature warehouse that maintains the complete historical record of all feature values.
Dual-Write Architecture: Flink typically implements a dual-write pattern, simultaneously writing the latest features to Redis for online serving and writing time-partitioned snapshots to OLAP databases for offline analysis and model training.
Tabular Model Inference
At this stage, we have prepared discrete feature sets for different prediction tasks. The inference service architecture is intentionally designed to be simple and efficient.
Inference Request Flow
The typical request flow for model inference consists of four steps:
- Request: Client sends a request containing an entity identifier (e.g.,
entity_id) - Feature Lookup: Service queries Redis to retrieve the feature vector for the entity
- Feature Vector Assembly: Retrieved features are assembled into the expected model input format
- Model Prediction: The trained model processes the feature vector and returns predictions
Feature Schema Consistency
The model expects exactly the same feature schema during inference as it received during training. This includes:
- Feature Names: Identical naming conventions
- Feature Order: The same sequence of features in the vector
- Normalization: Identical scaling and transformation methods
- Default Values: Consistent handling of missing features
To ensure this consistency, the inference service pins to a specific feature schema version, and Flink writes features using that same version identifier. Schema mismatches lead to silent model degradation, where the model continues to produce predictions but with significantly reduced accuracy.
Consistency Between Offline and Online Environments
Even when features are computed correctly, a critical challenge emerges from the architectural split:
- Training Data Source: Historical training data is extracted from OLAP databases
- Inference Data Source: Real-time inference reads from Redis
To prevent train-serve skew, the system must guarantee:
- Identical Feature Logic: The same computation logic must be applied in both Flink (for online features) and batch processing (for training data)
- Consistent Time Semantics: Time-based features (e.g., rolling windows) must use the same temporal boundaries
- Identical Transformations: All preprocessing, normalization, and encoding steps must be exactly replicated
Connection Between RDBMS and Flink: Change Data Capture
A critical question arises: when transactions are updated in the RDBMS, how does Flink detect these changes and automatically generate real-time features? This integration is achieved through Change Data Capture (CDC) and message-oriented middleware, typically Apache Kafka.
The CDC Pipeline Architecture
The complete data flow from operational database to real-time features follows this sequence:
-
Transaction Commit: When a new transaction occurs, the database writes these changes to its Write-Ahead Log (WAL), a durable transaction log used for crash recovery and replication.
-
Change Data Capture: A CDC tool (such as Debezium, Maxwell, or database-native CDC) continuously reads the database log and emits row-level change events. These events capture insertions, updates, and deletions at the granularity of individual rows.
-
Event Publishing: The CDC system publishes these change events to Kafka topics, with each database table typically corresponding to one or more Kafka topics. Kafka provides durable, ordered, and scalable event streaming.
-
Event Streaming: Kafka acts as a decoupling layer and does not interpret or transform transaction semantics—it simply provides reliable event delivery from the CDC source to Flink consumers.
-
Dynamic Table Abstraction: Flink consumes CDC topics and interprets them as dynamic tables. Each table becomes a dynamic stream of row changes, where updates are handled as retractions (delete old version) followed by insertions (insert new version). Conceptually, Flink perceives the RDBMS as a continuously evolving relational database rather than a static snapshot.
-
Incremental Feature Computation: Flink incrementally updates features based on these change events, eliminating the need for expensive full table recomputation or scanning operations. Only the affected entities and time windows are updated.
This CDC-based architecture enables near-real-time feature updates with minimal latency (typically seconds) while avoiding the performance impact on operational databases that would result from direct analytical queries.